Параллельные данные – это оригинальные тексты и их переводы в структурированном виде, т.е. каждому предложению на языке оригинала соответствует предложение на языке перевода. При настройке на параллельных данных система обучается таким образом, что адаптирует стиль и лексику данных, на которых она обучалась.
Для того, чтобы данные стали пригодны для обучения нейронной модели, они должны обладать следующими свойствами:



Однако даже в хороших данных могут быть ошибки, которые могут повлиять на качество модели, поэтому необходима предварительная подготовка данных для обучения.
Для подготовки данных для обучения в PROMT применяется разнообразные технологии. Например, базовая прочистка включает в себя:
А также применяются некоторые другие технологии. Подробнее
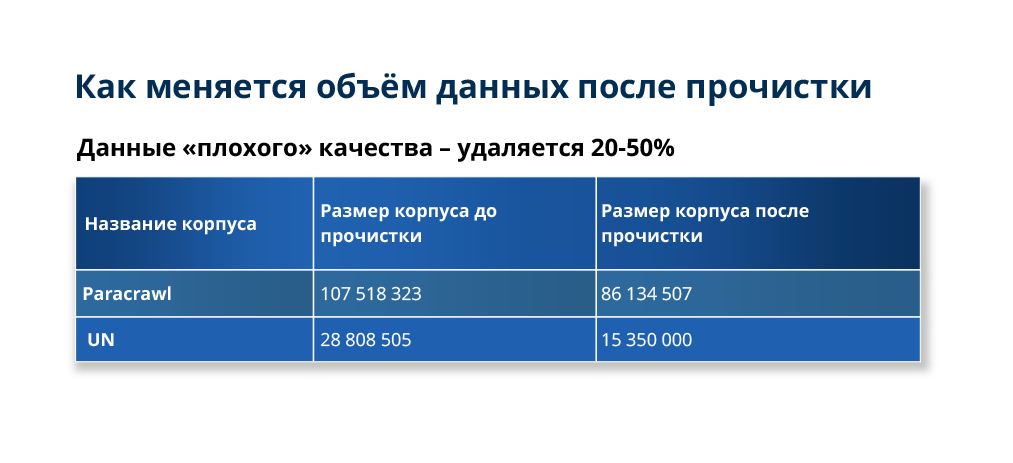
В процессе прочистки объем данных может значительно уменьшиться.


Достаточно часто обучение происходит в облаке, однако главным недостатком при таком подходе является уязвимость обрабатываемой информации. Как правило, данные для настройки носят конфиденциальных характер, что накладывает существенные ограничения на их использование на сторонних сервисах. Компания PROMT предлагает решения для настройки на стороне заказчика. При использовании PROMT Custom AI любая используемая информация защищена от утечки, так как обучение происходит на стороне заказчика.
PROMT Custom AI позволяет создавать специализированные модели перевода, которые подключаются к PROMT Neural Translation Server, PROMT Translation Factory и позволяют получать перевод, отличающийся высокой терминологической и стилистической точностью. Решение доступно для OC Linux.


Была проведена кастомизация решения PROMT на основе ранее выполненных переводов специалистами заказчика (почти 100 000 предложений и их переводов) и корпоративного глоссария из 2 000 терминов. В результате настройки рост качества перевода со специализированной нейронной моделью и глоссарием составил 10-15%
Сергей Кожевников, Консультант Управления информационно библиотечного обеспечения Центрального банка Российской Федерации«Сразу после внедрения мы видим рост заявок на перевод на английский беспрецедентно большого объема. Совершенно точно можно сказать, что без машинного перевода выполнить такой объем в поставленный срок было бы просто невозможно».
Полное описание кейса
![]() Решение включено в единый реестр российских программ.
Решение включено в единый реестр российских программ.
№ заявления (Linux) 11648
№ заявления (Windows) 11647
Подписаться на новости
Веб-форма не найдена.
